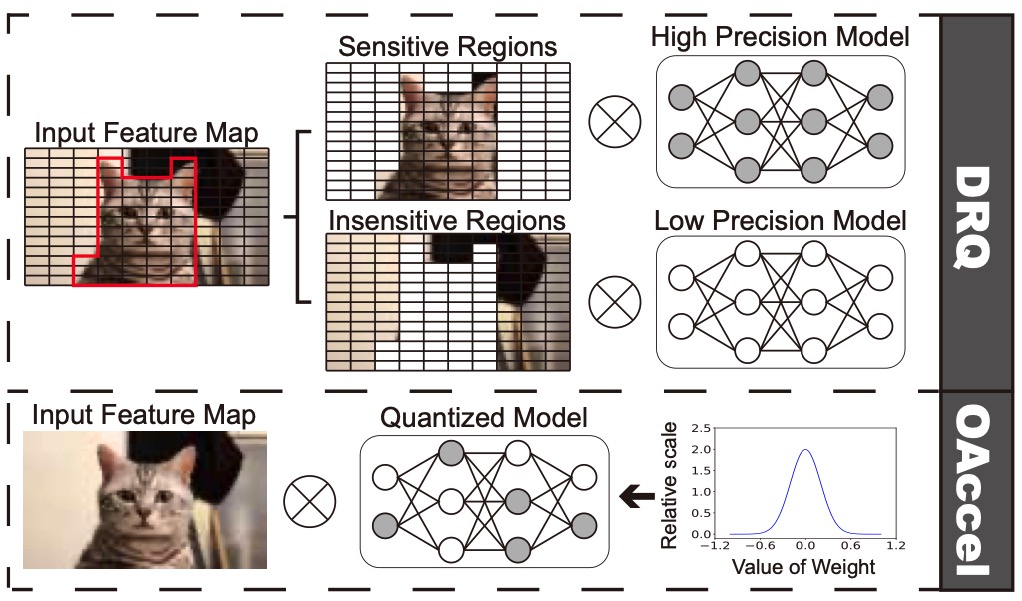
Quantization is an effective technique for Deep Neural Network (DNN) inference acceleration. However, conventional quantization techniques are either applied at network or layer level that may fail to exploit fine-grained quantization for further speedup, or only applied on kernel weights without paying attention to the feature map dynamics that may lead to lower NN accuracy. In this paper, we propose a dynamic region-based quantization, namely DRQ, which can change the precision of a DNN model dynamically based on the sensitive regions in the feature map to achieve greater acceleration while reserving better NN accuracy. We propose an algorithm to identify the sensitive regions and an architecture that utilizes a variable-speed mixed-precision convolution array to enable the algorithm with better performance and energy efficiency. Our experiments on a wide variety of networks show that compared to a coarse-grained quantization accelerator like “Eyeriss”, DRQ can achieve 92% performance gain and 72% energy reduction with less then 1% accuracy loss. Compared to the state-of-the-art mixed-precision quantization accelerator “OLAccel”, DRQ can also achieve 21% performance gain and 33% energy reduction with 3% prediction accuracy improvement which is quite impressive for inference.
Authors: Zhuoran Song, Bangqi Fu, Feiyang Wu, Zhaoming Jiang, Li Jiang, Naifeng Jing and Xiaoyao Liang.