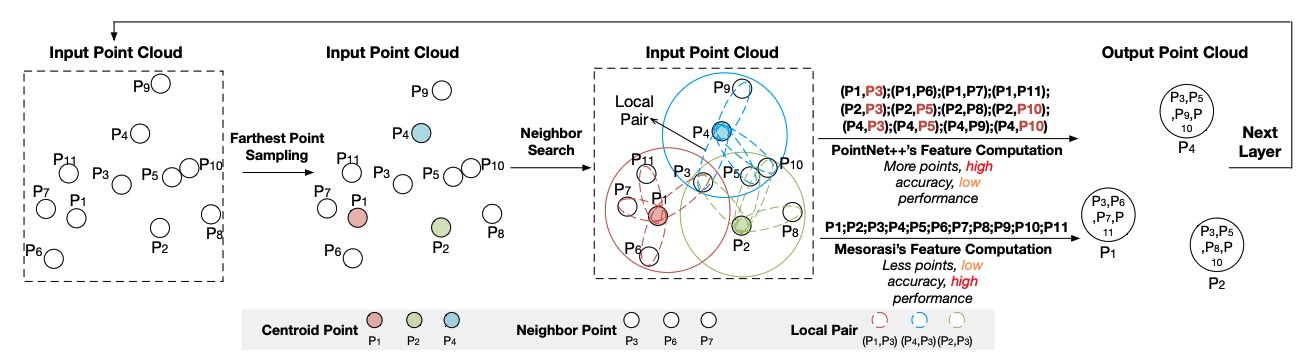
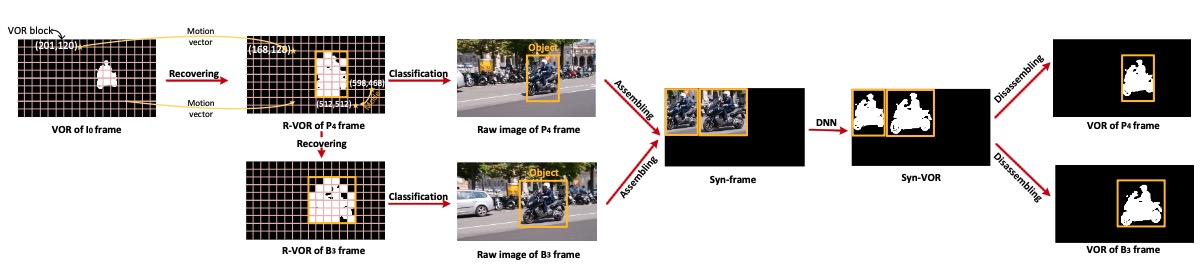
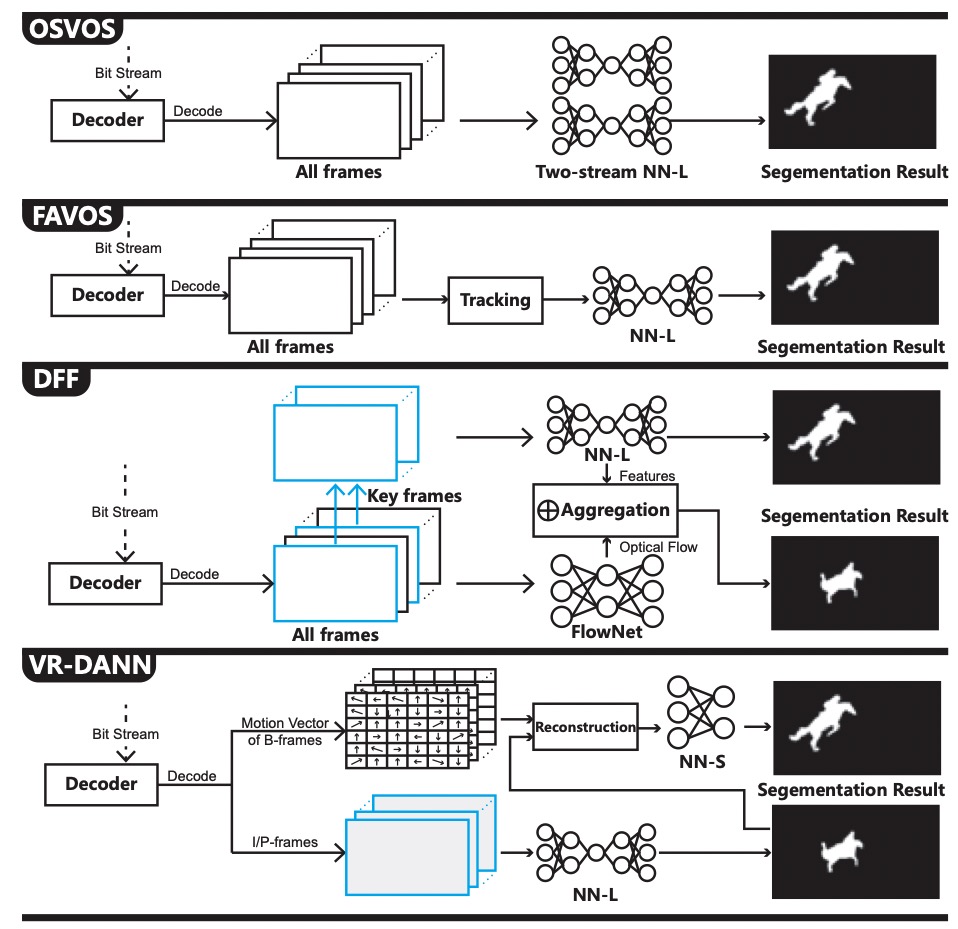
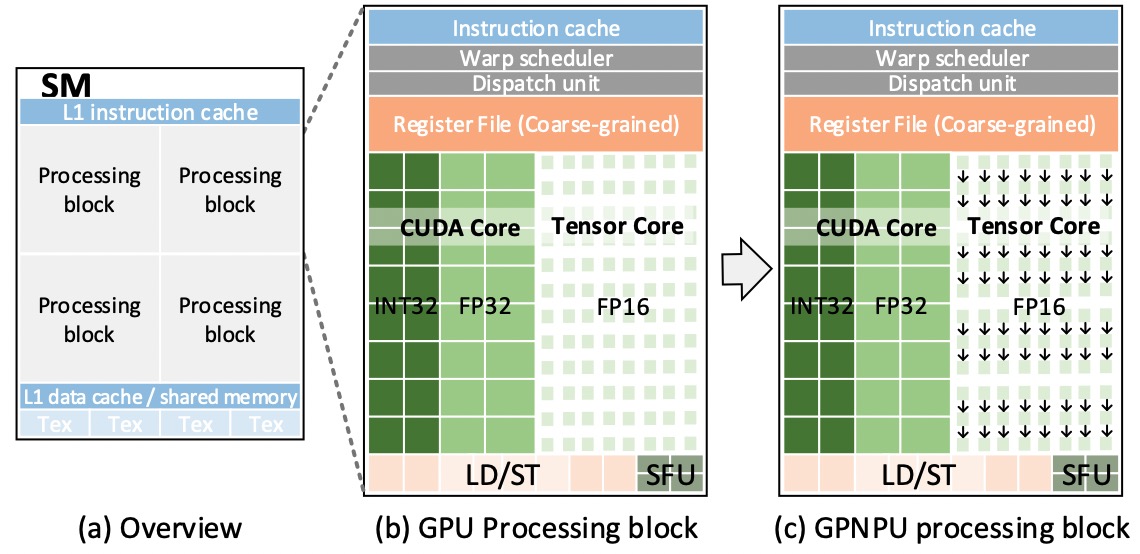
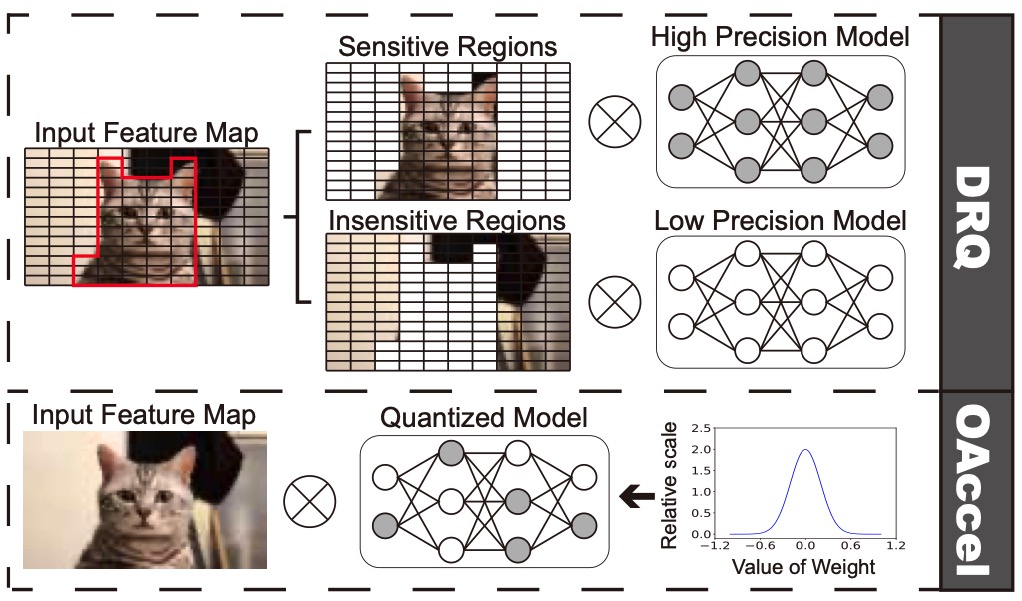
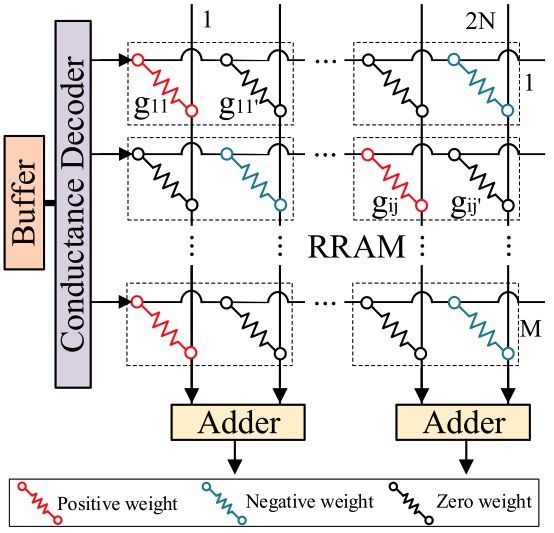
To tailor for DNN (Deep Neural Network) acceleration, GPU has migrated to new architectures such as NVIDIA Volta and Tur- ing that incorporate dedicated Tensor Cores. Although good at GEMM (generic matrix-matrix multiplication), Tensor Cores still have inefficiency facing convolutions with certain layer structures. This paper proposes a GPNPU (General-Purpose...
[Read More]