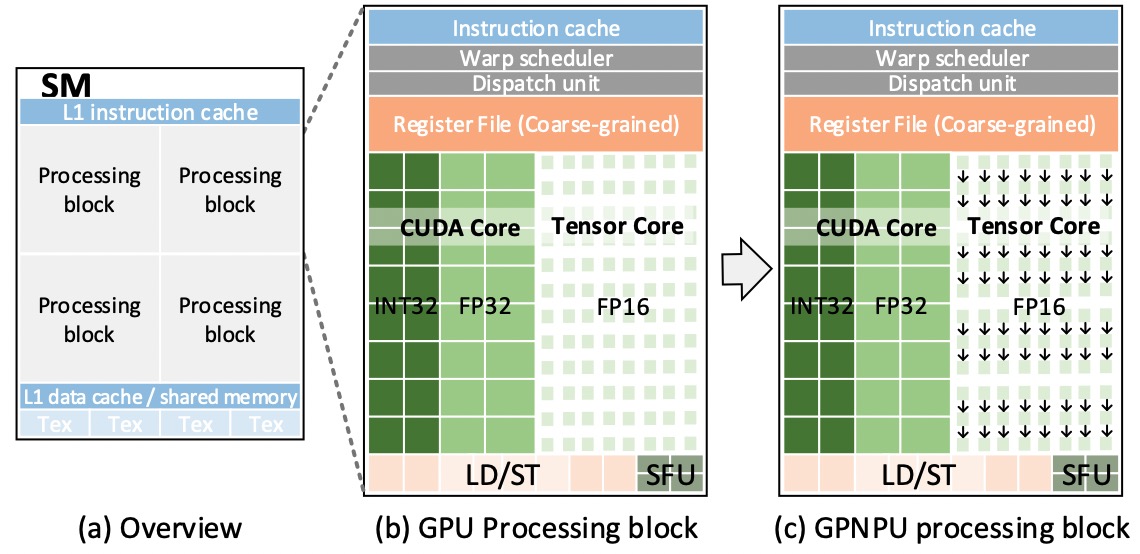
To tailor for DNN (Deep Neural Network) acceleration, GPU has migrated to new architectures such as NVIDIA Volta and Tur- ing that incorporate dedicated Tensor Cores. Although good at GEMM (generic matrix-matrix multiplication), Tensor Cores still have inefficiency facing convolutions with certain layer structures. This paper proposes a GPNPU (General-Purpose Neural-network Processing Unit) architecture, which offers another option of direct convolution in GPU. It stitches the direct convolution dataflow into the Tensor Cores with little hardware support, and resorts to regulated data layout with stripe-mined convolution execution to achieve higher performance and power efficiency, while retaining the general programability as GPU. We further apply a unified core design to support varied operand types and precision for higher computing throughput. The evaluation shows that GPNPU can outperform Tensor Cores on typical DNNs by 1.4X for inference (FP16) and 1.2X for training with much reduced power. The INT8 performance even increases to 2.4X. Our study demonstrates that it is possible and appealing to refine the Tensor Cores for greater DNN acceleration, while conforming to GPU architecture for the programmability necessary in future DNN evolution.
Authors: Zhuoran Song, Jianfei Wang, Tianjian Li, Li Jiang, Jing Ke, Xiaoyao Liang and Naifeng Jing.