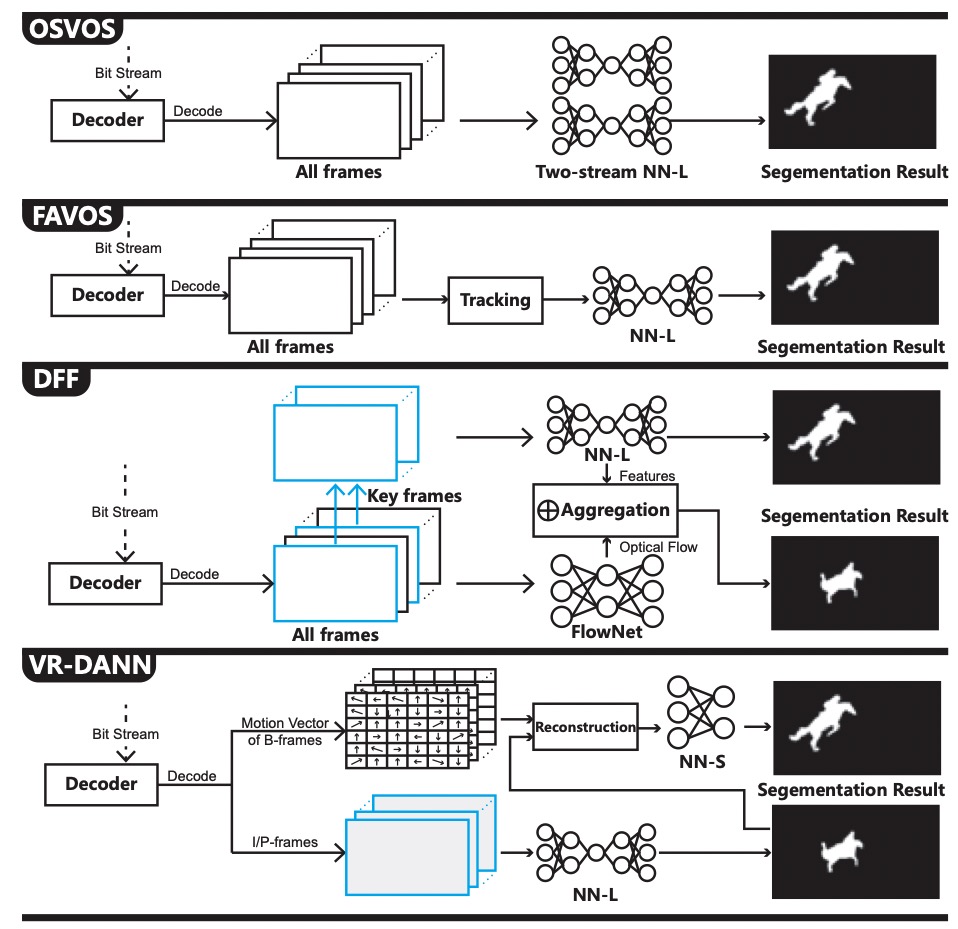
Nowadays, high-definition video object recognition (segmentation and detection) is not within the easy reach of a real-time task in a consumer SoC due to the limited on-chip computing power for neural network (NN) processing. Although many accelerators have been optimized heavily, they are still isolated from the intrinsic video compression expertise in a decoder. Given the fact that a great portion of frames can be dynamically reconstructed by a few key frames with high fidelity in a video, we envision that the recognition can also be reconstructed in a similar way so as to save a large amount of NN computing power. In this paper, we study the feasibility and efficiency of a novel decoder-assisted NN accelerator architecture for video recognition (VR-DANN) in a conventional SoC-styled design, which for the first time tightly couples the working principle of a video decoder with the NN accelerator to provide smooth high-definition video recognition experience. We leverage motion vectors, the simple tempo-spatial information already available in the decoding process to facilitate the recognition process, and propose a lightweight NN-based refinement scheme to suppress the non-pixel recognition noise. We also propose the corresponding microarchitecture design, which can be built upon any existing commercial IPs with minimal hardware overhead but significant speedup. Our experimental results show that the VR-DANN-parallel architecture achieves 2.9× performance improvement with less than 1% accuracy loss compared with the state-of-the-art “FAVOS” scheme widely used for video recogni- tion. Compared with optical flow assisted “DFF” scheme, it can achieve 2.2× performance gain and 3% accuracy improvement. As to another “Euphrates” scheme, VR-DANN can achieve 40% performance gain and comparable accuracy.
Authors: Zhuoran Song, Feiyang Wu, Xueyuan Liu, Naifeng Jing and Xiaoyao Liang.